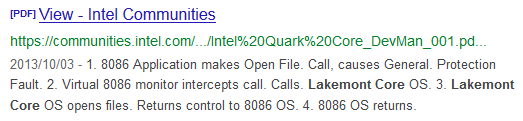
私が「Intel® Quark SoC X1000 Core Developer’s Manual October 2013」で「Lakemont Core」の記述を発見した際に、該当の「Figure 49. Virtual 8086 Environment Interrupt and Call Handling」が画像だから置き換えられずに残ったのでは、というようなことを「Intel Quark Core自体の仕様(コードネームはLakemont Core?)」で書いたのですが、見直してみたところ、実際にはそんなことはなく普通にPDFとして構成されている図でした。ではなぜ該当するPDF自体をAdobe Readerなどで開いて「Lakemont Core」を検索すると該当箇所がヒットしないのでしょうか?※1
実はこの部分、通常のUnicodeの範囲※2ではなく「(PDF)Supplementary Private Use Area-B – Unicode Consortium」の範囲のUnicode※3で記載されているからです。このため検索に引っかからなかったようです。これは、該当部分を作った人が意図的にリークを狙ったのか、作業上の理由でそうなっているのかは不明ですが、結果としてコードネームから実製品名への置き換えや、その後のチェックでなかなか気づきにくいことになっており、見過ごされることとなったようです。
ちなみに、昨日まではGoogle検索でも該当するPDFは引っかかっていませんでしたが、今朝のくらいから(?)引っかかるようになったようです。
- 私は検索してヒットしなかったので該当部分は画像なんだろうと勝手に思い込んでしまっていました。
- 通常のUnicode表現→「Lakemont Core」
- 該当PDFのUnicode表現→「※PHPまたはWordPressが対応していないために貼り付けられませんでした※」
U+10002F U+100044 U+10004E U+100048 U+100050 U+100052 U+100051 U+100057 U+100003 U+100026 U+100052 U+100055 U+100048